さて、ここ数日、ハードウェアの動作を勉強しようと思って、
このページを参考にしててちょこちょこプログラムをSchemeで書く為に格闘してました。
いやぁ、なかなかC言語を読むのが難しくて手こずってたんですが、ある程度カタチになったんで、メモ代わりに。
しっかし、Cのプログラム見てると、大域変数使いまくりで、破壊的変更ありーの、ポインタなんて出てきた日にゃあ何やってんだか一発で分からんし、ホント困ったもんですよ。
例によって、関数プログラミング的に解題していきたいと思います。
インタプリタとコンパイラ
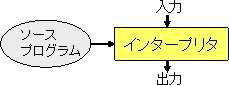
言語処理系とは、プログラミング言語で記述されたプログラムを計算機上で実 行するためのソフトウエアである。そのための構成として、大別して2つの構 成方法がある。
- インタープリター(interpreter,翻訳系): 言語の意味を解析しながら、その意味する動作を実行する。
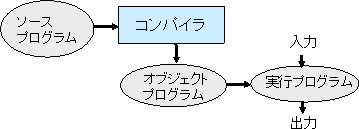
- コンパイラ(compiler,通訳系): 言語を他の言語に変換し、その言語の プログラムを計算機上で実行させるもの。狭い意味でコンパイラは、言語を機 械語に変換し、実行するものであるが、他の言語、あるいは仮想機械コードに 変換するものもコンパイラと呼ぶ。他の言語に変換するときには、特に translatorと呼ぶ場合もある。
元のプログラムをソースプログラム、 翻訳の結果と得られるプログラムをオブジェクトプログラムと呼ぶ。 機械語で直接、計算機上で実行できるプログラム を実行プログラムと呼ぶ。オブジェクトプログラムがアセンブリプログラムの 場合には、アセンブラにより機械語に翻訳されて、実行プログラムを得る。他 の言語の場合には、オブジェクトプログラムの言語のコンパイラでコンパイル することにより、実行プログラムが得られる。仮想マシンコードの場合には、 オブジェクトコードはその仮想マシンにより、インタプリトされて実行される。
はい、左様でやんすね。
言語処理系の基本構成
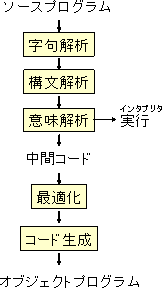
コンパイラにしてもインタプリターにしても、その構成は多くの共通部分を持 つ。すなわち、ソースプログラムの言語の意味を解釈する部分は共通である。 インタプリターは、解釈した意味の動作をその場で実行するのに対し、コンパ イラではその意味の動作を行うコードを出力する。
言語処理系は、大きく分けて、次のような部分からなる。
- 字句解析(lexical analysis): 文字列を言語の要素(トークン、token)の列に分解する。
- 構文解析(syntax analysis): token列を意味を反映した構造に変換。こ の構造は、しばしば、木構造で表現されるので、抽象構文木(abstract syntax tree)と呼ばれる。ここまでの言語を認識する部分を言語のparserと 呼ぶ。
- 意味解析(semantics analysis): 構文木の意味を解析する。インタプリ ターでは、ここで意味を解析し、それに対応した動作を行う。コンパイラでは、 この段階で内部的なコード、中間コードに変換する。
- 最適化(code optimization): 中間コードを変形して、効率のよいプログ ラムに変換する。
- コード生成(code generation): 内部コードをオブジェクトプログラムの 言語に変換し、出力する。例えば、ここで、中間コードよりターゲットの計算 機のアセンブリ言語に変換する。
コンパイラの性能とは、如何に効率のよいオブジェクトコードを出力できるか であり、最適化でどのような変換ができるかによる。インタープリタでは、プ ログラムを実行するたびに、字句解析、構文解析を行うために、実行速度はコ ンパイラの方が高速である。もちろん、機械語に翻訳するコンパイラの場合に は直接機械語で実行されるために高速であるが、コンパイラでは中間コードで やるべき操作の全体を解析することができるため、高速化が可能である。
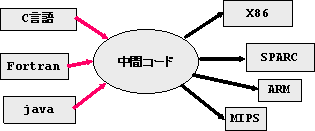
また、中間言語として、都合のよい中間コードを用いると、いろいろな言語か ら中間言語への変換プログラムを作ることで、それぞれの言語に対応したコン パイラを作ることができる。
まず、元々はその、字句解析と構文解析をどうやるんだ、ってのの疑問からスタートしたわけですが。
まあ、続けてやっていきましょうか。
例題: 式の評価
さて、例として最も簡単な数式の評価について、インタプリターとコンパイラ を作ってみることにする。目的は,
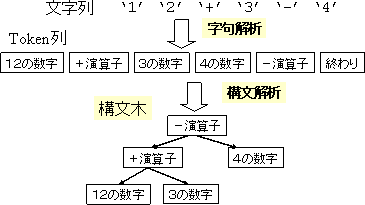
12 + 3 - 4
の式の入力に対し、この式を計算し、
11
と出力するプログラムを作ることである。これは、式という「プログラミング 言語」を処理する言語処理系である。「式」という言語では、tokenとして、 数字と"+"や"-"といった演算子がある。
まずは、字句解析ではこれらのトークンを認識する。例えば、上の例では、
12の数字、+の演算子、3の数字、-の演算子、4の数字、終わり
という列に変換する。
tokenは、tokenの種類と12の数字という場合の12の値の2つの組で表される。 以下にtokenの種類を定義するexprParser.hを示す。
とまあ、ここでCで書かれたソースが示されるんですが、色々やってみた結果、こういうヘッダファイルで定義される
#define マクロなんかはSchemeじゃ要らねぇな、ってのが分かりました。最初はCコードに則ってやってこう、って思ったんですが、どうも具合が良くないんでオミットです。何せ、Lisp系言語だとシンボルがそのまま使えるんでこういう「Cっぽい」定義は要らないですね。
字句解析を行う関数getTokenを示す。
さあて、これがまず最初凄くツマッてたトコなんですよね~。まず、
ungetcって何だ?とか思って(笑)。
良く分からんC言語の関数で、
調べてみると次のような事が書いてある。
読み込んだ文字を1文字押し戻すとは、どういう事なんだ?というわけですが、
戻すには ungetc()を使用します。
読み込んだ文字とは、、ファイル読み込みや、キーボードからの入力などの
ストリームと呼ばれるものから読み込んだ文字です。
その文字を、fgetc()や、getchar()などで読み込んだ後、
またもう1度ストリームに戻してしまう、というのが ungetc()の処理です。
うそぉん、ストリームから取ってきた文字をまたストリームに戻せるんかい、とか思って(笑)。さすがC言語(苦笑)。
あっれぇ、Schemeには
read-charに対して
unread-charなんてあっただろうか、と困ってたわけですね(笑)。当然無いですがね(苦笑)。
そんな時に
Sagittarius Schemeの作者の人から助け舟が。
あ、そう、こういう時
peek-charを使うんだ、って今回初めて知った次第です(笑)。ダメじゃん(笑)。
仕様書見ても良く分かんなかったもんな~。
[[手続き]] (peek-char)
[[手続き]] (peek-char port)
入力ポートportから取り出すことができる次の文字を返すが、次の文字を指し示す様なポートの更新は行なわれない(ポート内の位置は変わらない)。取り出す文字が存在しなかった場合はファイル終りオブジェクトが返される。port引数は省略でき、その場合のデフォルトはcurrent-input-portが返す値である。
注:
peek-charの呼び出しで返される値は、同じポートに対するread-charの呼び出しで返される値と同じものである。唯一の違いは、ポートに対する直後のread-char呼び出しもしくはpeek-char呼び出しで、直前のpeek-char呼び出しで返された値が返されるという点である。特に対話型ポートに対してpeek-charを呼び出した場合、入力を待ち続けてread-charがハングする時には、peek-charも必ずハングすることになる。
わりぃ、ホンマ、何言ってるんだかサッパリ分からん(苦笑)。
まあ、要するにこういう事らしいです。ストリームに例えば、"1 2 3 4 5"ってあった場合、
read-charは"1"を取ってきたあとストリームを"2 3 4 5"に更新するけど、
peek-charの場合は"1 2 3 4 5"から"1"を取ってもストリームを"1 2 3 4 5"のままに置いておくそうです。
まあ、敢えて言うと、こういう入出力系ってインタプリタで試しづらいんですよね。
read-charだとまだいいんですが、
peek-charだと無限ループみたいな事になって、何だか良く分からん事になります。
インタプリタ上のReaderで
'hogeと入力すると、ストリームに
'hogeが入って、次から
read-charを呼び出すと、ストリームに残ってた文字が一字づつ出力されていきます。
一方、
peek-charの場合、ポートが更新されないんで永遠に一文字目の
#\'がずーっと出力され続けますね。これを解除するにはもう一度
read-charを呼んでポートを更新しないといけません。
これさえ分かれば
CのソースをSchemeで書きなおすのは簡単です。
Scheme版では、
exprParser.hで大域変数として定義されてた
tokenValと
currentTokenの2つを
getTokenプロシージャ内部から多値で返すようにしています。わざわざ大域変数として定義して破壊的に変更するのも嫌ですしね。
この関数は、字句を読み込み、currentTokenにtokenの種類、NUMの場合に tokenValに値を返す。
だから、Scheme版は本当に値を返してますが、
オリジナルのCコードは返してませんね。大域変数を書き換えてるわけで、副作用目的の、要するに「手続き」がこのC版
getTokenの正体です。大体、関数の型が
voidですしね。
Scheme版
getTokenの動作は次のようになります。
"12 + 3 - 4"と言う入力を分解して、要素が数値の場合は
tokenValとしてその値を返し(数値じゃない場合は0)、それとその
tokenValの「情報」を
currentTokenとして返します。
こういうテストがC言語だとやりづらいトコロです(
main関数が無い状態だとどう動作してるんだか分かったモンじゃないし、要コンパイルなのが自明です)。
BNFと構文木
では、この「式」というプログラミング言語の構文とはどのようなものであろうか。例えば、次のような規則が構文である。
足し算の式 := 式 +の演算子 式
引き算の式 := 式 -の演算子 式
式 := 数字 | 足し算の式 | 引き算の式
|
このような記述を、BNF (Backus Naur Form または Buckus Normal Form) という。
このような構造を反映するデータ構造を作るのが、構文解析である。図に示す。
構文解析のデータ構造は、以下のような構造体を作る。これをexprParser.hに 定義しておく。
さて、ここでまた悩んだんですよね~。Schemeでも
record-typeを使って構造体で作るべきか?
大体、構造体絡むと破壊的変更が避けられなくなったりするんですよねぇ。しかも
Cのコード見ると、何だか循環参照のように見えるし・・・(
実は違うそうですが)。
結局、わざわざ構造体で構文木を定義するのは止めました。これはリストを持たない貧弱なCだから必要なんであって、SchemeなんかのLisp系言語では必要ない。要するに直接構文木(らしきもの)をリストを使って直接生成してやれば良い、って事です。
つまり、例えば上のような
[12の数字] [+演算子] [3の数字] [4の数字] [-演算子] [終わり]
と言うトークン列に対して
'([-演算子] ([+演算子] [12の数字] [3の数字]) [4の数字])
みたいなリストを生成して返してやれば良い、って事です。しかも、連想リストを生成するようにしてみます。
この構文木を作るプログラムが、readExpr.cである。 このプログラムでは、exprParser.hで定義されて いるASTを使って、構文木を作っている。このデータ構造は 式の場合は、演算子とその左辺の式と右辺の式を持つ。数字の場合はこれらを 使わずに値のみを格納する。tokenを読むたびに、データ構造を作っている。
ASTは定義しない事にしましたが、tokenを読むたびにデータ構造を作り出して、構文木のデータ構造を作って返すのはLispではお手の物です。次が等価のScheme版
readExprです。
オリジナルのコードだと、大域変数が
getToken呼び出す度に書き換えられてて、その破壊的変更をアテにするプログラミングな為、これを関数プログラミングで再現するにはどうすりゃエエんだ、ってんで結構悩んだんですよねぇ。本当だったらもっと綺麗に書けたんじゃねぇの、って若干心残りがあるんですが、一応オリジナルのロジックを出来るだけ尊重するようにはしてみました。
また、
オリジナル版だと、破壊的変更前提の無引数の手続きなんですが、Scheme版だと、やっぱり
tokenValと
currentTokenを受け取るプロシージャにしています。
では、動作を見てみます。
さっきの設計と真逆になってるように見えますが、これで良いのです。そもそも、連想リストだと順序には意味がありません。
基本的な構文構造を表現する連想リスト(構文木リスト = AST)は
'((op . currentToken) (val . tokenVal) (left . 左の枝) (right . 右の枝))
となっていて、valは数値の時にしか生成されず、また、leftやrightの中も再帰的にASTが収まっていきます。
解釈実行: インタプリター
この構文木を解釈して実行する、すなわちインタプリターをつくってみること にする。その動作は、
- 式が数字であれば、その数字を返す。
- 式が演算子を持つ演算式であれば、左辺と右辺を解釈実行した結果を、 演算子の演算を行い、その値を返す。
このプログラムがevalExpr.cである。 evalExpr.cは、構文木ASTを解釈して、解釈する。
- 数字のASTつまり、opがNUMであれば、その値を返す。
- 演算式であれば、左辺を評価した値と右辺を評価した値をopに格納さ れている演算子にしたがって、計算を行う。
これらは再帰的に呼び出しが行われていることに注意しよう。
まあ、今までも何度かインタプリタは書いてきましたが、構文木を使って、ってのは初めてですね。
構造はほぼ
オリジナルのコードと同じです。特に手を加えてはいません。
しっかし、ひっさしぶりに末尾再帰じゃない再帰コード書いたんで気持ち悪いですね(笑)。
オリジナルのC版も、これじゃあ大して効率良く無いんじゃないでしょうか。あー、そうか、コンパイラ書く為の前フリか(笑)。
evalExprの動作テストは以下の通り。
キチンと計算されてますね。
mainプログラムでは、関数readExprを呼び、構文木を作り、それを関数 evalExprで解釈実行して、その結果を出力する。これが、インタプリターであ る。先のプログラムと大きく違うのは、式の意味を表す構文木が内部に生成さ れていることである。この構文木の意味を解釈するのがインタプリターである。 (readExprでは1つだけ先読みが必要であるので、getTokenを呼び出している)
うーん、正直、なんで
if(currentToken != EOL){
printf("error: EOL expected\n");
exit(1);
}
なんてのがあるんだか分からないですね。これねぇ方が動くんだけど・・・。
まあいいや、上記のコード部分を除いてSchemeで書いた
mainプロシージャが次になります。
さっき書いたテストまんまそのまんまですね。
では動作確認です。
完璧ですね。
ではScheme版インタプリタのソースコード全容を。
では、次はいよいよコンパイラ、です。
コンパイラとは
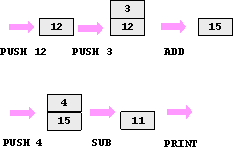
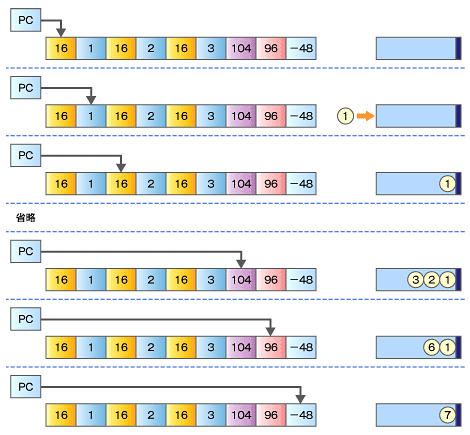
次にコンパイラをつくってみる。コンパイラとは、解釈実行する代わりに、実 行すべきコード列に変換するプログラムである。実行すべきコード列は、通常、 アセンブリ言語(機械語)であるが、そのほかのコードでもよい。中間コード として、スタックマシンのコードを仮定することにする。スタックマシンは以 下のコードを持つことにする。
- PUSH n : 数字nをスタックにpushする。
- ADD : スタックの上2つの値をpopし、それらを加算した結果をpushする。
- SUB : スタックの上2つの値をpopし、減算を行い、pushする。
- PRINT: スタックの値をpopし、出力する。
コンパイラは、このスタックマシンのコードを使って、式を実行するコード列 を作る。例えば、図で示した例の式12+3-4は下のようなコードになる。
PUSH 12
PUSH 3
ADD
PUSH 4
SUB
PRINT
|
スタックマシンでの実行は以下のように行われる。
stackCode.hには、コードとその列を格納する領域を定義してある。
この辺の定義もSchemeには要らないですね。シンボルとリストで凌ぎましょう。
コンパイルの手順は、以下のようになる。
- 式が数字であれば、その数字をpushするコードを出す。
- 式が演算であれば、左辺と右辺をコンパイルし、それぞれの結果をスタッ クにつむコードを出す。その後、演算子に対応したスタックマシンのコードを 出す。
- 式のコンパイルしたら、PRINTのコードを出しておく。
この中間コードを生成するのが、compileExpr.cである。構文木を入力して、 再帰的に上のアルゴリズムを実行する。コードはCodesという配列に格納して おく。
さて、
compileExprですが、Scheme版では2つに分けました。
一つは構文木を受け取って、上のロジックに従って命令のリストを生成する
Codes、もう一つは構文木を受け取って
Codesを呼び出し、結果のリストを反転させた後、
vector(Cで言う配列にあたる)に変換する
compileExprです。
ちなみに、
Codesが全体的に生成するのは、見た目は連想リストですが、連想リストではありません。と言うのも、今回生成するのはアセンブリ的なリストなんで「順序が重要」だからです。連想リストはハッシュ的に順序は重要じゃないんで、リストとして順序を保持したままベクタへ変換する必要性があるから、です(ただし、要素は連想リストです)。
では動作テストです。
見て分かる通り、"12 + 3 - 4"と言う入力が、opcodeとoperandと言う2つのキーを持つ、連想リストを5要素としたベクタ(配列)に変換されています。ベクタの番号0~4は結果、実行順序を表してる事になりますね。
コード生成では、ここではスタックマシンのコードをCに直して出力すること にしよう。Cで実行させるために、mainにいれておくことにする。このプログ ラムが、codeGen.cである。
Cで書いてきたのにCで出力する、なんつーのはバカっぽいな、とか思ったんですが(笑)、郷に入りては郷に従え、でSchemeで書いてきたのにSchemeで出力します(爆)。
ちなみに、最初は、
オリジナルのコードに従って書いてたんですが、上手く動いたのをきっかけにしてもうちょっと欲が出てきたんですね。
元のコードにはいくつかちょっと特徴があります。
- スタックマシンが別にあるわけじゃなくって、スタックマシン自体も毎回コンパイルで生成してる。
- printfが多用されているが、結果的にCコードである「文字列」を生成してるだけである。従って本来なら、Cコードを生成する文字列をでっち上げるのが実は大半の本質的作業である。
つまり、SchemeでSchemeコードを生成するにせよ
- スタックマシン自体を毎回生成してるようなコードを吐いて構わない。
- 結局文字列を生成、加工するだけで良い
と言う2点が極めて重要なんです。それでスタックマシン用のコードをSchemeのコードとして変換出来るわけです。
それで、もう一つあって、最初はSchemeコードを生成する際、これは大方、破壊的変更を多用した「いわゆる」スタックマシンをSchemeで書いてるように生成すれば良いのかな、って思ってたんですが、生成されるコードも関数プログラミング様式で生成出来ないか、って思い直したわけです。
初め、それは大変なんじゃないか、って思ってたんですが、出力を噛まさずに文字列だけで操作するなら、むしろ再帰と相性が良い、ってのが分かったんですね。
っつーか、Lispなんかの関数プログラミングだと、プログラミングやってる側だと書くのも読むのも大変になるネストの深さになるわけですが、そこはコンパイラ、全く人間の「可読性」関係無く文字列操れるじゃん、ってぇんで書いてみたのが次のコードになります。
ちょっとどういうSchemeコードを生成するのか、見てみましょうか。
最後の
(codeGen code)ってのでSchemeコードを生成するわけですね。
前半の部分は言わばテンプレで、毎回
codeGenが呼び出される度に「スタックマシン」を生成します。
実際に
codeGenが毎回生成してるのが
mainプロシージャの部分で、結果、
"12 + 3 - 4"
と言う入力が、
(define (main)
(sub
(push 4
(add
(push 3
(push 12
'()))))))
に書き換えられてて、これはホント、そのまま関数プログラミングでのスタイルです。空リストをスタックに見立てて、内側のプロシージャは外側へと結果を返して、外側のプロシージャはそれを引数として受け取って・・・って連鎖してるわけですね。
ぶっちゃけ、人としてはあまり書きたくないスタイルですが(笑)、コンパイラなら別にへっちゃらで言われた通りに変換していってくれて、実はコード生成は、再帰を使う限り、こっちの方が(この例だと)簡単なんじゃないか、ってカンジです。
コンパイラのmainプログラムであるが、readExprまではインタープリタと同じ である。標準出力に出力されるプログラムに適当に名前をつけ(たとえば、 output.c)これをCコンパイラでコンパイルして実行すればよい。(assembler のファイルの場合はasコマンドでコンパイルする。)
そう、
displayせずにファイルに書き出せば、要するにコンパイラとして機能する、って事です。これは面白い。
例えば、実験として、次のような式を入力してもガンガン「関数型」のコードに変換してくれます。
すげぇバカバカしいんですが、面白いです(笑)。なかなか構文解析とかコンパイラ書くのって面白いな、って感動しました。
コンパイラの全ソースコードは次のようなものです。
ちょっと暫くこの辺のネタで遊んでみますかね。